



There’s the sexy side of SEO, like writing splashy content, getting to know bigwig influencers on Twitter and hustling for those Grade-A links.
And then there’s on-site SEO, the … less-sexy side.
On-site SEO (also called on-page or technical SEO) is the process of making your website as search engine- and user-friendly as possible. It’s all about speaking a language search engine spiders can understand so that they can better match your content with what searchers are asking for.
And while it may not be the most glamorous part of SEO, that doesn’t make on-site SEO any less important.
Spiders are getting smarter, but they still need our help as webmasters. The more information you can provide via on-site SEO, the less a search engine spider has to assume – leading to better positioning for your site.
With the help of webmasters, our spider friends can understand not only what a page is about, but also what it’s designed to do. But how? Let’s take Raven Tools’ new Site Auditor for a spin and go over some on-site SEO elements in detail.

The Site Auditor gives you a nice breakdown of on-site SEO opportunities in 6 primary categories: visibility, meta, content, links, images and semantics. This post will go over the first three. In part 2, I’ll discuss links, images, semantics and page speed.
Visibility issues
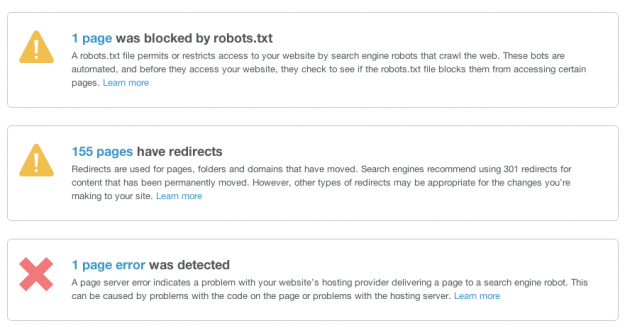
Visibility means ensuring that every important page of your website can appear in search engine results and returns a proper response when a person (or a robot) visits it.
The main elements of visibility are robots.txt and redirects, or status codes.
robots.txt
If your site includes content that you don’t want the search engines spiders to crawl, you’ll need a robots.txt file. This simple text file is the first thing a spider will encounter when crawling your website. It contains two pieces of information:
- The disallow command, which informs a search engine which files and directories it should not crawl or index
- A sitemap reference, which points the search engine to your XML sitemap
- The disallow command, which informs a search engine which files and directories it should not crawl or index
The robots.txt file should be placed at the root of your website, a la http://raventools.com/robots.txt.
Redirects/status codes
You may think of the internet as a space-like entity, but in reality, every website lives on a computer somewhere. All of the files needed to render a web page, HTML, style sheets, images, exist on a hard drive, and the web server delivers them upon request via a URL.
That’s where status codes come in. These are codes associated with the different response types that can be returned by a server whenever a page is requested.
The primary response codes to be aware of are 200 – OK (best status code ever), 404 – Page Not Found (not good, but better if you have an awesome custom 404 page) and 301 – Moved Permanently.
SEOs mention 301 redirects a lot, primarily because it’s a way to maintain link flow should a page URL change or a page retired.
Site Auditor will display all redirect status codes so you can determine whether those pages need your attention.
Meta issues
In addition to text content that human visitors can see, webmasters can also add text that is specifically for robots.
Metadata – including title and meta description – works behind the scenes to provide search engines with information that will either help them understand what a page is about or correctly display the page in search results.
Leaving meta elements blank will force the search engine to make assumptions about your content and provide its own title and description.
Page titles
The page title (normally) becomes the link that appears in Google search results for your page. Keywords become bold (which can draw the eye) and it’s recommended that you keep the length of your page title to less than 70 characters.
Your page title should contain the keywords the page is mostly about without stuffing or repeating terms. Use common sense: if a page title looks like spam, it probably is.
Site Auditor will show you which of your page titles are missing, too short, too long or duplicated.
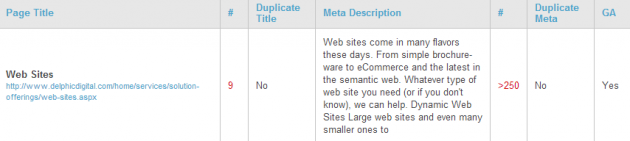
Meta description
The meta description tag is believed to have little SEO value, but is very important to your page’s click-through rate (CTR).
The meta description usually appears directly after the link as a summary like so.

An optimized meta description should be written as a call to action and should contain at least one of your target keywords. Google will bold terms in the meta description that match the query, much like in the page title.
It’s recommended that you have unique meta descriptions throughout your site and keep them to 140 characters or less, both of which Site Auditor checks for.
Content issues
The content section of the Site Auditor is extremely important. It shows both low word count and more importantly, duplicate content.

Low word count
Low word count doesn’t mean it’s time to stuff your page full of keywords. Instead, think of how you can enhance the value of each page with content that is a resource or can help someone make a decision.
Duplicate content
Duplicate content can be a very serious SEO problem if not addressed – and the Site Auditor makes it easy to find.
Fixing these issues may require that you make decisions about your website’s page content, page titles and even your entire information architecture.
Remember: optimize for your audience first. Too much duplicate or low-quality content can send the wrong signals about your brand to both human visitors and spiders.
Next week: Part 2
In Part 2, I’ll discuss links, images, semantics and page speed as evaluated by Raven’s Site Auditor.
Meanwhile, sound off in the comments if you have questions about specific factors mentioned in this post.
Photo Credit: Anne*°(goutte à goutte) via Compfight cc

Analyze over 20 different technical SEO issues and create to-do lists for your team while sending error reports to your client.
Possibly I’m weird, but I consider this pretty sexy work. Finding and fixing problems? So robots can understand your work? Hot.
Nice post, Chris.
Haha, not weird at all 🙂 Thanks!
Great post, definitely waiting for part 2 to come.
Also, it would be nice if you could dedicate a bit more time to the problem of duplicate content, currently I’m using http://www.plagspotter.com/ to indicate pages with duplicated content, but I’m still not sure how to properly fight it. Especially when it comes to off-page duplicate content (like rss feeds and content scrappers). Would be nice to see more information on this topic as well.
Thanks!
Thanks, Bradley. Duplicate content as a penalty relates to content on your own website, not cross-domain. You can report duplicate content here: http://support.google.com/webmasters/bin/answer.py?hl=en&answer=93713
If you use WordPress, Yoast’s SEO plugin can help you combat scrapers by adding a link back to your website in your RSS feeds: http://yoast.com/wordpress/seo/
Thanks a lot for these links, I’ll take a look at them now.
You’re welcome!
Hey guys,
Just wanted to let you know that this and some other posts are listed as “uncategorized” and may be harder to find than if you put them into a specific category. Thanks again for the opportunity!
Hi Chris,
Thanks for the heads up! It’s some back-end WordPress stuff that’s going on. Hope to have it fixed soon.
Awesome article! Lucky for me I don’t have to wait for part 2. As it’s already out.